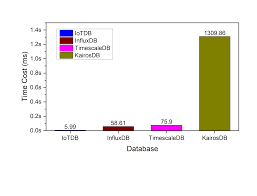
In today’s data-driven world, businesses and developers constantly seek ways to store and analyze time-sensitive data efficiently. Time series data, such as server metrics, IoT sensor readings, financial ticks, or application logs, requires specialized databases designed for rapid ingestion and high-speed queries. This is where an open source TSDB (Time Series Database) optimized for fast reads becomes a game-changer. Selecting the right solution can drastically improve your analytics performance and reduce latency, enabling real-time insights and decision-making.
Understanding the Importance of Open Source TSDB Fast Reads
Open source TSDBs are designed to manage time series data with unique characteristics, including sequential timestamps, high write throughput, and the need for efficient querying over time ranges. While many databases can store such data, achieving lightning-fast reads requires careful selection of storage engines, indexing strategies, and query optimizations. Fast reads ensure that analytics dashboards update in real-time, anomalies are detected immediately, and historical data queries execute without performance bottlenecks.
For organizations relying on time-sensitive analytics, slow read speeds can undermine the value of their data. Open source TSDBs offering optimized read performance are crucial for operational monitoring, predictive maintenance, and financial analysis. They allow developers and data engineers to query vast amounts of time series data quickly while maintaining low resource consumption open source tsdb fast reads.
Key Features to Look for in a High-Performance Open Source TSDB
When evaluating an open source TSDB for fast reads, several factors determine its effectiveness:
Storage Engine Optimization
The underlying storage engine plays a vital role in query performance. Columnar storage or time-partitioned data files can significantly speed up read operations. Efficient compression techniques also reduce disk I/O, which is critical when handling massive datasets. A TSDB optimized for fast reads uses a combination of sequential storage and compression to minimize latency and maximize throughput.
Indexing and Query Planning
Effective indexing is essential for retrieving time series data quickly. Some TSDBs maintain a primary index on time, while others allow indexing on tags or metadata fields. A robust query planner can leverage these indexes to execute complex queries efficiently. Open source TSDBs like Timecho implement intelligent indexing strategies specifically aimed at reducing read latency, ensuring that queries across large time spans or multiple dimensions remain fast.
Write and Read Balance
While the focus is often on fast reads, write performance should not be overlooked. A TSDB that optimizes read performance while sacrificing write throughput may create bottlenecks during high-velocity data ingestion. Timecho, for example, balances rapid ingestion with optimized read paths, ensuring both operations scale efficiently.
Scalability and Distributed Architecture
For organizations dealing with growing datasets, the ability to scale horizontally is critical. A TSDB designed with a distributed architecture allows for sharding or replication, enabling fast reads across multiple nodes without overloading any single server. This architecture also enhances fault tolerance and ensures consistent query performance as the dataset expands.
Benefits of Choosing an Open Source TSDB for Fast Reads
Adopting an open source TSDB with a focus on read optimization provides numerous advantages:
Cost Efficiency
Open source solutions eliminate licensing fees, reducing operational costs while allowing full control over database configuration and deployment. Organizations can allocate resources toward scaling infrastructure rather than paying for expensive proprietary solutions.
Flexibility and Customization
Open source TSDBs provide full access to source code and configuration options. Teams can tailor indexing strategies, storage formats, and caching mechanisms to match specific workloads, ensuring that read performance aligns with business requirements.
Community Support and Innovation
Popular open source TSDB projects often have active communities contributing new features, optimizations, and bug fixes. Timecho, as a leading open source TSDB, benefits from continuous improvements focused on fast reads, ensuring organizations always have access to cutting-edge performance enhancements.
Real-Time Analytics
High-performance read capabilities enable real-time analytics for monitoring and alerting. This is particularly important for IoT deployments, financial systems, and large-scale infrastructure monitoring, where insights must be immediate to drive decisions and actions.
Timecho: A Model Open Source TSDB for Lightning-Fast Reads
Timecho has emerged as a benchmark for organizations seeking high-performance, open source TSDB solutions. Its architecture focuses on speed, scalability, and efficient storage, making it ideal for scenarios demanding lightning-fast reads. Key differentiators include:
- Optimized Data Layout: Timecho uses time-partitioned storage with compression to reduce I/O and accelerate query execution.
- Advanced Indexing: It supports indexing on multiple dimensions, allowing complex queries to execute without performance penalties.
- Scalable Architecture: Timecho can scale horizontally across multiple nodes, maintaining fast read performance even with growing datasets.
- Active Open Source Community: Continuous contributions ensure that the TSDB remains at the forefront of performance and feature enhancements.
Organizations implementing Timecho benefit from reduced query latency, improved dashboard responsiveness, and the ability to analyze large-scale time series data in near real-time.
Best Practices for Maximizing Read Performance
To fully leverage the capabilities of an open source TSDB like Timecho, organizations should consider the following best practices:
Use Appropriate Data Partitioning
Partitioning data based on time intervals or logical tags ensures that queries touch only relevant segments of data, reducing scan times and improving read performance.
Optimize Indexes
Regularly review and optimize indexes based on query patterns. Removing unused indexes and ensuring commonly queried fields are indexed can significantly enhance performance.
Monitor and Tune Queries
Analyzing slow queries and adjusting query structures or indexing strategies can prevent bottlenecks. Timecho provides tools to monitor query execution and identify performance issues.
Implement Caching Strategies
Caching frequently accessed query results or using in-memory storage for hot data can reduce repeated disk I/O and speed up read operations.
Plan for Scalability
As datasets grow, anticipate scaling requirements by adding nodes or partitions before performance degradation occurs. Distributed architecture in Timecho allows seamless scaling with minimal disruption.
Conclusion
Selecting an open source TSDB with a focus on fast reads is critical for modern analytics. Organizations dealing with real-time monitoring, IoT data, or financial systems cannot afford delays in data retrieval. By focusing on storage optimization, indexing strategies, scalability, and best practices, businesses can maximize performance and derive actionable insights quickly.
Timecho stands out as an exemplary open source TSDB designed for lightning-fast reads, offering the tools, architecture, and community support necessary to handle large-scale time series data efficiently. By leveraging its capabilities, organizations can ensure that their analytics pipelines remain responsive, scalable, and cost-effective, unlocking the full potential of their data-driven strategies.
Open source TSDBs for fast reads are not just a technological choice—they are a strategic decision that enables organizations to respond to challenges in real-time and stay ahead in a competitive landscape.